파이썬의 시각화 라이브러리 -시본(Seaborn)
파이썬의 대표적인 시각화 도구로는 matplotlib과 seaborn이 있습니다. seaborn은 matplotlib 대비 손쉽게 그래프를 그리고 그래프 스타일 설정을 할 수 있다는 장점이 있습니다. 정교하게 그래프의 크기를 조절하거나 각 축의 범례 값을 조절할 때에는 matplotlib을 함께 사용해야하지만, seaborn 사용법에 익숙해진다면 큰 문제가 되진 않습니다.
아래 표는 Seaborn 라이브러리에서 제공해주는 그래프(plot)의 종류를 정리한 내용입니다.
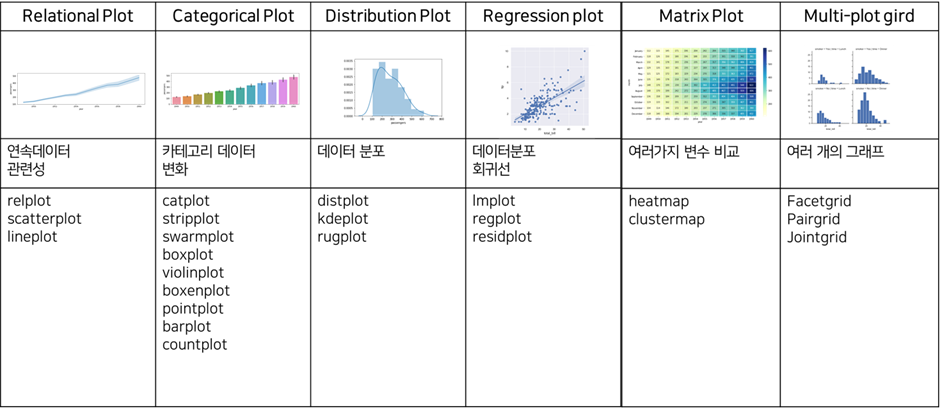
다양한 종류의 plot을 제공하기 때문에 처음에는 어떤 그래프를 가져다 써야할지 막막합니다. 모든 plot의 사용법을 숙지할 필요는 없습니다. 데이터의 종류가 연속형 데이터인지, 카테고리 데이터인지, 내가 궁금한 내용이 데이터의 시계열적 변화인지 분포인지에 따라 적합한 그래프를 선택해서 도식화하는 방법을 익힌다면 충분합니다.
이번 장에서는 Seaborn 라이브러리에서 제공하는 plot의 종류를 가장 기본적인 형태로 정리해보겠습니다.
라이브러리 임포트
우선 seaborn 라이브러리를 사용하고 데이터 프레임을 다루기 위해 라이브러리 임포트를 합니다.
#라이브러리 임포트
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
#seaborn에서 제공하는 flights 데이터 셋을 사용
flights = sns.load_dataset('flights')
#그래프 사이즈 설정
plt.figure(figsize=(12, 3))
Barplot
sns.barplot(data=flights, x="year", y="passengers")
막대그래프를 그리는 barplot입니다. flights 데이터 프레임의 x 축에는 year 컬럼의 값을, y 축에는 passengers 컬럼의 값을 도식화합니다. x축에 사용한 year값은 정수형 데이터로 barplot을 그리기 적합한 형태의 데이터입니다. 만약 x축으로 사용할 값이 소숫점을 포함한 실수형의 연속데이터라면 barplot이 굉장히 세밀하게 표시되어 그래프를 이해하기 어려운 형태가 될 것입니다. barplot과 같이 Categorical Plot을 사용할 때에는 실수타입의 연속형 데이터가 x축에 설정되지 않도록 하는 것이 좋습니다.

barplot의 각각의 값에 검정색 막대가 꽂혀 있는 것은 데이터의 신뢰구간을 나타냅니다. barplot은 각각의 x축(연도) 값에 대해 하나의 대표값을 y축(승객 수)으로 설정해야하므로 데이터의 평균값을 사용하여 표시하게 됩니다. 예를 들어 1949년에 승객수가 100명인 날도 있고, 120명인 날도 있었는데 평균인 110을 기준으로 그래프를 그리게 되는 것입니다. 데이터의 4분위수 기준으로 상세한 분포를 도식화하고 싶다면 violinplot이나 swarmplot을 사용하는 것이 더욱 효과적입니다.
Boxplot
sns.boxplot(data=flights, x="year", y="passengers")

Violineplot
sns.violinplot(data=flights, x="year", y="passengers")

Swarmplot
sns.swarmplot(data=flights, x="year", y="passengers")
Boxplot, Violinplot, Swarmplot은 barplot과 유사하게 x축(연도)별 y축(승객 수) 값을 표시하지만, 하나의 대표값으로 표시하는 것이 아니라 데이터의 분포를 확인할 수 있도록 표시합니다.

Lineplot
sns.lineplot(data=flights, x="year", y="passengers")
선 그래프를 도식화한 lineplot입니다. 위에서 그린 barplot과 동일한 x, y축 데이터를 설정하였습니다.

barplot의 가장 상위 점을 하나의 선으로 이은 형태의 그래프가 그려졌습니다. 선 주변의 옅은 파란색은 데이터의 신뢰구간을 표시한 것입니다 .즉 1950년에는 y축 데이터(승객수)가 약 150부근에 대부분 몰려있었다면 1960년에는 400~500 사이에 분포한 것을 확인할 수 있습니다.
Distplot
displot은 하나의 데이터에 대해 분포를 확인할 때 사용합니다.
sns.distplot(flights["passengers"])
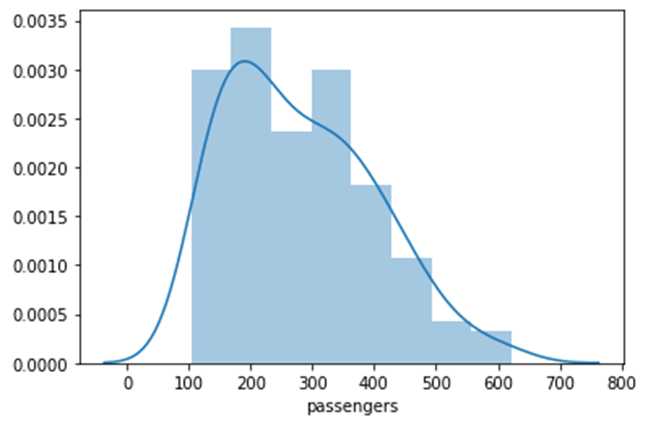
승객 데이터는 100~300 사이에 많이 분포해있다는 것을 확인할 수 있습니다. displot에서는 막대(bin)를 사용한 히스토그램과 밀도를 선으로 이은 kde plot이 함께 그려집니다. 파라미터 설정을 통해 막대의 개수와 kde선 표시 여부 등을 추가로 설정할 수 있습니다.
'데이터과학' 카테고리의 다른 글
| 파이썬의 시각화 라이브러리 - 맷플롯립(Matplotlib) (0) | 2021.06.08 |
|---|---|
| 파이썬의 컴퓨팅 라이브러리 - 사이파이(SciPy) (0) | 2021.06.08 |
| 파이썬의 컴퓨팅 라이브러리 - 넘파이(NumPy) (1) | 2021.06.08 |
| 파이썬에서 데이터 가져오기 및 내보내기 (0) | 2021.06.08 |



